Modelagem preditiva de óbitos por SRAG com dados do Open Data SUS 2023, usando Regressão Logística e XGBoost.
Autor
Luiz Felipe P. Figueiredo
Data de Publicação
16/04/2025
Este notebook tem como objetivo analisar a base de dados de Síndrome Respiratória Aguda Grave (SRAG) referente ao ano de 2023, com foco em compreender os fatores associados à evolução dos casos e aplicar modelos preditivos para prever óbitos.
Dicionário de Dados
O dicionário de dados utilizado nessa analise é o dicionário disponível no link abaixo. Ele contém as definições da maioria das variáveis.
import numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom scipy.stats import chi2_contingencyfrom sklearn.model_selection import KFoldfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import ( confusion_matrix, classification_report, roc_auc_score, roc_curve, accuracy_score, precision_score, recall_score, f1_score)from sklearn.preprocessing import StandardScaler, OneHotEncoderfrom sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelinefrom imblearn.over_sampling import SMOTE# Lendo a basedados = pd.read_csv('INFLUD23-24-03-2025.csv', sep=';', encoding='latin1', low_memory=False)# Visualizando as primeiras linhasdados.shapedados.head()
DT_NOTIFIC
SEM_NOT
DT_SIN_PRI
SEM_PRI
SG_UF_NOT
ID_REGIONA
CO_REGIONA
ID_MUNICIP
CO_MUN_NOT
ID_UNIDADE
CO_UNI_NOT
CS_SEXO
DT_NASC
NU_IDADE_N
TP_IDADE
COD_IDADE
CS_GESTANT
CS_RACA
CS_ESCOL_N
ID_PAIS
CO_PAIS
SG_UF
ID_RG_RESI
CO_RG_RESI
ID_MN_RESI
CO_MUN_RES
CS_ZONA
SURTO_SG
NOSOCOMIAL
AVE_SUINO
FEBRE
TOSSE
GARGANTA
DISPNEIA
DESC_RESP
SATURACAO
DIARREIA
VOMITO
OUTRO_SIN
OUTRO_DES
PUERPERA
FATOR_RISC
CARDIOPATI
HEMATOLOGI
SIND_DOWN
HEPATICA
ASMA
DIABETES
NEUROLOGIC
PNEUMOPATI
IMUNODEPRE
RENAL
OBESIDADE
OBES_IMC
OUT_MORBI
MORB_DESC
VACINA
DT_UT_DOSE
MAE_VAC
DT_VAC_MAE
M_AMAMENTA
DT_DOSEUNI
DT_1_DOSE
DT_2_DOSE
ANTIVIRAL
TP_ANTIVIR
OUT_ANTIV
DT_ANTIVIR
HOSPITAL
DT_INTERNA
SG_UF_INTE
ID_RG_INTE
CO_RG_INTE
ID_MN_INTE
CO_MU_INTE
UTI
DT_ENTUTI
DT_SAIDUTI
SUPORT_VEN
RAIOX_RES
RAIOX_OUT
DT_RAIOX
AMOSTRA
DT_COLETA
TP_AMOSTRA
OUT_AMOST
PCR_RESUL
DT_PCR
POS_PCRFLU
TP_FLU_PCR
PCR_FLUASU
FLUASU_OUT
PCR_FLUBLI
FLUBLI_OUT
POS_PCROUT
PCR_VSR
PCR_PARA1
PCR_PARA2
PCR_PARA3
PCR_PARA4
PCR_ADENO
PCR_METAP
PCR_BOCA
PCR_RINO
PCR_OUTRO
DS_PCR_OUT
CLASSI_FIN
CLASSI_OUT
CRITERIO
EVOLUCAO
DT_EVOLUCA
DT_ENCERRA
DT_DIGITA
HISTO_VGM
PAIS_VGM
CO_PS_VGM
LO_PS_VGM
DT_VGM
DT_RT_VGM
PCR_SARS2
PAC_COCBO
PAC_DSCBO
OUT_ANIM
DOR_ABD
FADIGA
PERD_OLFT
PERD_PALA
TOMO_RES
TOMO_OUT
DT_TOMO
TP_TES_AN
DT_RES_AN
RES_AN
POS_AN_FLU
TP_FLU_AN
POS_AN_OUT
AN_SARS2
AN_VSR
AN_PARA1
AN_PARA2
AN_PARA3
AN_ADENO
AN_OUTRO
DS_AN_OUT
TP_AM_SOR
SOR_OUT
DT_CO_SOR
TP_SOR
OUT_SOR
DT_RES
RES_IGG
RES_IGM
RES_IGA
ESTRANG
VACINA_COV
DOSE_1_COV
DOSE_2_COV
DOSE_REF
FAB_COV_1
FAB_COV_2
FAB_COVREF
LAB_PR_COV
LOTE_1_COV
LOTE_2_COV
LOTE_REF
FNT_IN_COV
DOSE_2REF
FAB_COVRF2
LOTE_REF2
TRAT_COV
TIPO_TRAT
OUT_TRAT
DT_TRT_COV
CO_DETEC
VG_OMS
VG_OMSOUT
VG_LIN
VG_MET
VG_METOUT
VG_DTRES
VG_ENC
VG_REINF
REINF
FAB_ADIC
LOT_RE_BI
FAB_RE_BI
DOSE_ADIC
DOS_RE_BI
LOTE_ADIC
TABAG
0
21/01/2023
3
20/01/2023
3
MG
DIAMANTINA
1450.0
ARACUAI
310340
HOSPITAL SAO VICENTE DE PAULO ARACUAI
2134276
F
04/05/1940
82
3
3082
9
1.0
1
BRASIL
1
MG
DIAMANTINA
1450
ARACUAI
310340.0
1.0
2.0
2.0
2.0
1.0
1.0
2.0
1.0
2.0
1.0
2.0
2.0
2.0
NaN
2.0
1.0
2.0
2.0
2.0
2.0
2.0
1.0
2.0
2.0
2.0
2.0
2.0
NaN
NaN
NaN
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
1.0
21/01/2023
MG
DIAMANTINA
1450
ARACUAI
310340
2.0
NaN
NaN
NaN
6
NaN
NaN
1.0
21/01/2023
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
5.0
NaN
2
1
27/01/2023
27/01/2023
25/01/2023
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
2.0
2.0
2.0
NaN
NaN
NaN
2
21/01/2023
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1
08/02/2023
6
23/01/2023
4
RS
014 CRS
1602.0
CAMPINA DAS MISSOES
430370
POSTO DE SAUDE SEDE E PACS CAMPINA DAS MISSOES
2250225
M
01/07/1941
81
3
3081
6
1.0
1
BRASIL
1
RS
014 CRS
1602
CAMPINA DAS MISSOES
430370.0
2.0
2.0
2.0
2.0
2.0
1.0
2.0
1.0
1.0
2.0
2.0
2.0
NaN
NaN
2.0
1.0
2.0
2.0
2.0
2.0
2.0
2.0
2.0
1.0
1.0
2.0
2.0
NaN
1.0
CA PROSTATA
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
01/02/2023
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
2.0
5
ESPESSAMENTO DE PAREDES BRONQU
01/02/2023
1.0
08/02/2023
1.0
NaN
1.0
10/02/2023
2.0
NaN
NaN
NaN
NaN
NaN
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
5.0
NaN
1
3
02/03/2023
02/03/2023
08/02/2023
0.0
NaN
NaN
NaN
NaN
NaN
1.0
NaN
NaN
NaN
1.0
2.0
2.0
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
16/03/2021
13/04/2021
28/10/2021
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
87 - COVID-19 PFIZER - COMIRNATY
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
210051
210132
FG3531
2.0
07/06/2022
85 - COVID-19 ASTRAZENECA/FIOCRUZ - COVISHIELD
21OVCD316Z
9.0
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2
14/02/2023
7
13/02/2023
7
SC
FLORIANOPOLIS
1476.0
FLORIANOPOLIS
420540
INSTITUTO DE ENSINO E PESQUISA DR IRINEU MAY B...
19402
M
26/09/1946
76
3
3076
6
1.0
NaN
BRASIL
1
SC
FLORIANOPOLIS
1476
FLORIANOPOLIS
420540.0
1.0
NaN
2.0
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
ASSINTOMATICO
NaN
1.0
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
13/02/2023
SC
FLORIANOPOLIS
1476
FLORIANOPOLIS
420540
2.0
NaN
NaN
3.0
NaN
NaN
NaN
1.0
13/02/2023
4.0
SWAB NASOFARINGEO
2.0
14/02/2023
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
4.0
NaN
1
1
17/02/2023
20/02/2023
14/02/2023
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
5.0
VIDRO FOSCO
13/02/2023
NaN
NaN
5.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
1.0
20/03/2021
17/04/2021
NaN
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
NaN
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
210075
210132
NaN
2.0
30/07/2022
87 - COVID-19 PFIZER - COMIRNATY
FP7498
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
3
16/02/2023
7
04/02/2023
5
SP
GVE XXIV RIBEIRAO PRETO
1348.0
CAJURU
350940
CASA DE CARIDADE SAO VICENTE DE PAULO CAJURU
2023016
F
19/02/2004
18
3
3018
5
1.0
NaN
BRASIL
1
SP
GVE XXIV RIBEIRAO PRETO
1348
CAJURU
350940.0
2.0
2.0
NaN
NaN
1.0
1.0
1.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
04/07/2023
SP
GVE XXIV RIBEIRAO PRETO
1348
CAJURU
350940
NaN
NaN
NaN
3.0
2
NaN
NaN
1.0
07/02/2023
1.0
NaN
4.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
5.0
NaN
2
1
NaN
16/02/2023
22/02/2023
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
4.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
31/08/2021
28/10/2021
19/07/2022
87 - COVID-19 PFIZER - COMIRNATY
87 - COVID-19 PFIZER - COMIRNATY
87 - COVID-19 PFIZER - COMIRNATY
87 - COVID-19 PFIZER - COMIRNATY
FF2591
FG3533
FT7280
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
4
26/02/2023
9
26/02/2023
9
CE
1 CRES FORTALEZA
1519.0
FORTALEZA
230440
SOPAI HOSPITAL INFANTIL
2526638
M
03/04/2021
1
3
3001
6
4.0
5
BRASIL
1
CE
1 CRES FORTALEZA
1519
FORTALEZA
230440.0
1.0
NaN
NaN
NaN
1.0
1.0
1.0
2.0
1.0
2.0
2.0
2.0
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
26/02/2023
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.0
28/02/2023
1.0
NaN
2.0
01/03/2023
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
4.0
NaN
1
1
03/03/2023
03/03/2023
26/02/2023
0.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
2.0
2.0
2.0
NaN
NaN
NaN
NaN
NaN
5.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
1.0
22/09/2021
04/06/2021
NaN
87 - COVID-19 PFIZER - COMIRNATY
86 - COVID-19 SINOVAC/BUTANTAN - CORONAVAC
NaN
87 - COVID-19 PFIZER - COMIRNATY
FF8842
210223
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
2.0
NaN
NaN
NaN
NaN
NaN
NaN
NaN
Código
# Tamanho da baseprint(f"Total de registros: {dados.shape[0]}")print(f"Total de colunas: {dados.shape[1]}")
Total de registros: 278976
Total de colunas: 190
2. Filtragem Inicial
Código
# Valores únicos presentes na variável respostavalores_unicos = dados['EVOLUCAO'].unique()print("Valores únicos em 'EVOLUCAO':", valores_unicos)# Porcentagem de valores ausentesporcentagem_nulo = dados['EVOLUCAO'].isnull().mean() *100print(f"\nPorcentagem de valores nulos em 'EVOLUCAO': {porcentagem_nulo:.2f}%")
Valores únicos em 'EVOLUCAO': ['1' '3' nan '9' '2' '15/' '10/' '20/']
Porcentagem de valores nulos em 'EVOLUCAO': 4.96%
Código
# Definindo valores inválidos para removervalores_invalidos = ['3', '9', '10/', '15/', '20/']# Filtrando a basedados_filtrados = dados[ (dados['EVOLUCAO'].isin(['1', '2'])) # mantém só 1 e 2].copy()# Convertendo para inteiro para facilitar uso posteriordados_filtrados['EVOLUCAO'] = dados_filtrados['EVOLUCAO'].astype(int)# Exibindo forma final da baseprint(f"Shape original: {dados.shape}")print(f"Shape após remoção de nulos e inválidos: {dados_filtrados.shape}")# Verificando distribuição dos valores restantesprint("\nDistribuição de EVOLUCAO:")print(dados_filtrados['EVOLUCAO'].value_counts(normalize=True))
Shape original: (278976, 190)
Shape após remoção de nulos e inválidos: (250820, 190)
Distribuição de EVOLUCAO:
EVOLUCAO
1 0.900482
2 0.099518
Name: proportion, dtype: float64
3. Remoção de Colunas com Muitos Valores Ausentes
Código
# Verifica a porcentagem de valores nulos por colunaporcentagem_nulo = dados_filtrados.isnull().mean() *100# Exibe a porcentagem de nulos (opcional)print("Porcentagem de valores nulos por coluna:")print(porcentagem_nulo)# Remove as colunas com mais de 90% de valores nulosdados_filtrados = dados_filtrados.loc[:, porcentagem_nulo <90]# Exibe as colunas removidas (opcional)colunas_removidas = porcentagem_nulo[porcentagem_nulo >=90].index.tolist()print("\nColunas removidas (>= 90% nulos):")print(colunas_removidas)
# Lista consolidada das colunas a remover (alta taxa de nulos + descrições livres)colunas_para_remover = ['DT_TOMO', 'POS_AN_FLU', 'POS_AN_OUT', 'MORB_DESC', 'OUTRO_DES','POS_PCROUT', 'POS_PCRFLU', 'LOTE_REF2', 'FAB_COVRF2', 'DOSE_2REF','DT_SAIDUTI', 'DS_AN_OUT', 'DS_PCR_OUT', 'HISTO_VGM']# Remoção das colunas, se existiremdados_filtrados = dados_filtrados.drop(columns=[col for col in colunas_para_remover if col in dados_filtrados.columns])
Código
colunas_administrativas_remover = ['SEM_NOT', 'SEM_PRI', 'SG_UF_NOT', 'ID_REGIONA', 'CO_REGIONA','CO_MUN_NOT', 'ID_UNIDADE', 'CO_UNI_NOT', 'ID_PAIS', 'CO_PAIS','ID_RG_RESI', 'CO_RG_RESI', 'ID_MN_RESI', 'CO_MUN_RES','SG_UF_INTE', 'ID_RG_INTE', 'CO_RG_INTE', 'ID_MN_INTE', 'CO_MU_INTE','DT_DIGITA', 'ID_MUNICIP', 'TP_IDADE', 'COD_IDADE']# Remover colunas administrativas da base finaldados_filtrados = dados_filtrados.drop(columns=[col for col in colunas_administrativas_remover if col in dados_filtrados.columns])
Código
colunas_dt_remover = ['DT_EVOLUCA', 'DT_RAIOX', 'DT_RES_AN', 'DT_PCR','DT_COLETA', 'DT_ENCERRA', 'DT_NASC']dados_filtrados = dados_filtrados.drop(columns=[col for col in colunas_dt_remover if col in dados_filtrados.columns])
5. Conversão de Datas Importantes e Geração de Flags
Código
# Datas úteiscolunas_dt_util = ['DT_SIN_PRI', 'DT_NOTIFIC', 'DT_INTERNA', 'DT_ENTUTI']# Converter para datetimefor col in colunas_dt_util: dados_filtrados[col] = pd.to_datetime(dados_filtrados[col], errors='coerce', dayfirst=True)# Flags bináriasdados_filtrados['FOI_INTERNADO'] = dados_filtrados['DT_INTERNA'].notnull().astype(int)dados_filtrados['ENTROU_UTI'] = dados_filtrados['DT_ENTUTI'].notnull().astype(int)# Remover colunas de data que viraram flagscolunas_para_remover = ['DT_INTERNA', 'DT_ENTUTI']dados_filtrados = dados_filtrados.drop(columns=[col for col in colunas_para_remover if col in dados_filtrados.columns])
Código
# Lista de colunas a remover (irrelevantes + opcionais)colunas_para_remover = [# Colunas irrelevantes'LOTE_1_COV', 'LOTE_2_COV', 'LOTE_REF','FAB_COV_1', 'FAB_COV_2', 'FAB_COVREF','LAB_PR_COV', 'CO_DETEC', 'SURTO_SG', 'DOSE_REF', 'DOSE_2_COV', 'DOSE_1_COV' ,'TP_TES_AN', 'TP_AMOSTRA', 'ESTRANG']# Remover colunas do DataFramedados_filtrados = dados_filtrados.drop(columns=[col for col in colunas_para_remover if col in dados_filtrados.columns])
6. Ajustes de Lógica para Variáveis Dependentes do Sexo
Código
# Homens → valor 6 (não se aplica)dados_filtrados.loc[dados_filtrados['CS_SEXO'] =='M', 'CS_GESTANT'] =6# Mulheres com valor ausente → valor 9 (ignorado)dados_filtrados.loc[ (dados_filtrados['CS_SEXO'] =='F') & (dados_filtrados['CS_GESTANT'].isnull()),'CS_GESTANT'] =9
Código
# Todos os homens são marcados como "não puérpera" (2)dados_filtrados.loc[dados_filtrados['CS_SEXO'] =='M', 'PUERPERA'] =2# Mulheres com valor ausente → marcar como "ignorado" (9)dados_filtrados.loc[ (dados_filtrados['CS_SEXO'] =='F') & (dados_filtrados['PUERPERA'].isnull()),'PUERPERA'] =9
7. Imputação de Valores Faltantes com 9
Código
# Lista geral de colunas com NaN a serem imputadas com 9 (exceto datas e variáveis de tempo)colunas_a_imputar = ['PUERPERA', 'OBESIDADE', 'HEPATICA', 'SIND_DOWN', 'HEMATOLOGI','RENAL', 'IMUNODEPRE', 'DOSE_REF', 'PNEUMOPATI', 'NEUROLOGIC','ASMA', 'DIABETES', 'OUT_MORBI', 'CARDIOPATI', 'DOSE_2_COV','DOSE_1_COV', 'VACINA', 'TOMO_RES', 'CS_ESCOL_N', 'RAIOX_RES','PERD_PALA', 'PERD_OLFT', 'OUTRO_SIN', 'DOR_ABD', 'DIARREIA','GARGANTA', 'VOMITO', 'FADIGA', 'TRAT_COV', 'ANTIVIRAL','SATURACAO', 'DESC_RESP', 'AVE_SUINO', 'FEBRE', 'DISPNEIA','SUPORT_VEN', 'UTI', 'NOSOCOMIAL', 'RES_AN', 'TOSSE','PCR_RESUL', 'CS_ZONA', 'CRITERIO', 'REINF', 'CLASSI_FIN','HOSPITAL', 'AMOSTRA', 'SG_UF', 'VACINA_COV', 'FNT_IN_COV']for col in colunas_a_imputar:if col in dados_filtrados.columns: dados_filtrados[col] = dados_filtrados[col].fillna(9)
Código
# Calculando porcentagem de nulosporcentagem_nulos = dados_filtrados.isnull().mean() *100# Organizando em ordem alfabéticaporcentagem_nulos_ordenado = porcentagem_nulos.sort_values(ascending=False)# Exibindo como lista formatadafor coluna, porcentagem in porcentagem_nulos_ordenado.items():print(f"{coluna}: {porcentagem:.2f}% de valores faltantes")
DT_NOTIFIC: 0.00% de valores faltantes
DT_SIN_PRI: 0.00% de valores faltantes
CS_SEXO: 0.00% de valores faltantes
NU_IDADE_N: 0.00% de valores faltantes
CS_GESTANT: 0.00% de valores faltantes
CS_RACA: 0.00% de valores faltantes
CS_ESCOL_N: 0.00% de valores faltantes
SG_UF: 0.00% de valores faltantes
CS_ZONA: 0.00% de valores faltantes
NOSOCOMIAL: 0.00% de valores faltantes
AVE_SUINO: 0.00% de valores faltantes
FEBRE: 0.00% de valores faltantes
TOSSE: 0.00% de valores faltantes
GARGANTA: 0.00% de valores faltantes
DISPNEIA: 0.00% de valores faltantes
DESC_RESP: 0.00% de valores faltantes
SATURACAO: 0.00% de valores faltantes
DIARREIA: 0.00% de valores faltantes
VOMITO: 0.00% de valores faltantes
OUTRO_SIN: 0.00% de valores faltantes
PUERPERA: 0.00% de valores faltantes
FATOR_RISC: 0.00% de valores faltantes
CARDIOPATI: 0.00% de valores faltantes
HEMATOLOGI: 0.00% de valores faltantes
SIND_DOWN: 0.00% de valores faltantes
HEPATICA: 0.00% de valores faltantes
ASMA: 0.00% de valores faltantes
DIABETES: 0.00% de valores faltantes
NEUROLOGIC: 0.00% de valores faltantes
PNEUMOPATI: 0.00% de valores faltantes
IMUNODEPRE: 0.00% de valores faltantes
RENAL: 0.00% de valores faltantes
OBESIDADE: 0.00% de valores faltantes
OUT_MORBI: 0.00% de valores faltantes
VACINA: 0.00% de valores faltantes
ANTIVIRAL: 0.00% de valores faltantes
HOSPITAL: 0.00% de valores faltantes
UTI: 0.00% de valores faltantes
SUPORT_VEN: 0.00% de valores faltantes
RAIOX_RES: 0.00% de valores faltantes
AMOSTRA: 0.00% de valores faltantes
PCR_RESUL: 0.00% de valores faltantes
CLASSI_FIN: 0.00% de valores faltantes
CRITERIO: 0.00% de valores faltantes
EVOLUCAO: 0.00% de valores faltantes
DOR_ABD: 0.00% de valores faltantes
FADIGA: 0.00% de valores faltantes
PERD_OLFT: 0.00% de valores faltantes
PERD_PALA: 0.00% de valores faltantes
TOMO_RES: 0.00% de valores faltantes
RES_AN: 0.00% de valores faltantes
VACINA_COV: 0.00% de valores faltantes
FNT_IN_COV: 0.00% de valores faltantes
TRAT_COV: 0.00% de valores faltantes
REINF: 0.00% de valores faltantes
FOI_INTERNADO: 0.00% de valores faltantes
ENTROU_UTI: 0.00% de valores faltantes
8. Conversão de Tipos e Limpeza Fina
Código
# converter colunas float64 para intfor col in dados_filtrados.columns:if dados_filtrados[col].dtype =='float64': dados_filtrados[col] = dados_filtrados[col].astype('Int64')
Código
# Remover registros com idade negativadados_filtrados = dados_filtrados[dados_filtrados['NU_IDADE_N'] >=0].copy()# Corrigir valor 0 em CS_GESTANT → substituir por 9 (ignorado)dados_filtrados.loc[dados_filtrados['CS_GESTANT'] ==0, 'CS_GESTANT'] =9# Remover registros com SG_UF = '9'dados_filtrados = dados_filtrados[dados_filtrados['SG_UF'] !='9'].copy()
Código
# Função para verificar tipos únicos em cada colunadef encontrar_colunas_mistas(df): colunas_mistas = {}for col in df.columns: tipos = df[col].map(type).nunique()if tipos >1: colunas_mistas[col] = df[col].map(type).value_counts()return colunas_mistas# Aplicando a função no seu DataFramecolunas_com_dados_mistos = encontrar_colunas_mistas(dados_filtrados)# Exibindo os resultadosfor coluna, tipos in colunas_com_dados_mistos.items():print(f"\nColuna: {coluna}")print(tipos)
# Lista das colunas que você quer converter para intcolunas_para_int = ['CS_ESCOL_N', 'RAIOX_RES', 'CRITERIO']# Converter para int, tratando possíveis valores não convertíveisfor col in colunas_para_int: dados_filtrados[col] = pd.to_numeric(dados_filtrados[col], errors='coerce').astype('Int64') # Usa tipo nulo-friendly# Garantir que SG_UF está como stringdados_filtrados['SG_UF'] = dados_filtrados['SG_UF'].astype(str)
Documentação de Código - Tratamento e Pré-processamento da Base SRAG 2023
Aqui está descrito todas as etapas de tratamento e pré-processamento aplicadas aos dados da base de internações por Síndrome Respiratória Aguda Grave (SRAG) de 2023 acima, visando garantir transparência, reprodutibilidade e compreensão total do pipeline de limpeza dos dados. Todas as etapas foram realizadas levando em consideração o dicionário de dados disponível no link acima.
1. Carregamento da Base
Leitura da base: Arquivo INFLUD23-24-03-2025.csv, separado por ;, codificação latin1.
Visualização inicial: Verificação de dimensões e das primeiras linhas.
Análise da variável resposta (EVOLUCAO):
Identifica valores exclusivos presentes.
Calcula a porcentagem de valores nulos.
2. Filtragem Inicial
Mantidos apenas os registros com EVOLUCAO igual a 1 ou 2 (óbito ou cura).
Conversão da variável EVOLUCAO para inteiro para facilitar modelagem posterior.
3. Remoção de Colunas com Muitos Valores Ausentes
Cálculo da porcentagem de valores ausentes por coluna.
Remoção de colunas com 90% ou mais de dados nulos.
Lista das colunas removidas.
4. Remoção de Colunas Irrelevantes
Colunas descritivas livres e redundantes: como MORB_DESC, OUTRO_DES, entre outras.
Colunas administrativas: como SG_UF_NOT, CO_MUN_NOT, ID_REGIONA, entre outras.
Colunas de datas que não são informativas: como DT_NASC, DT_EVOLUCA, DT_RAIOX, etc.
Colunas sobre vacinação, lote, fabricante e outras consideradas não essenciais.
5. Conversão de Datas Importantes e Geração de Flags
Colunas de data relevantes (DT_SIN_PRI, DT_NOTIFIC, DT_INTERNA, DT_ENTUTI) foram convertidas para datetime.
Foram criadas duas variáveis binárias:
FOI_INTERNADO: 1 se DT_INTERNA não é nula.
ENTROU_UTI: 1 se DT_ENTUTI não é nula.
As datas usadas nessas flags foram então removidas.
6. Ajustes de Lógica para Variáveis Dependentes do Sexo
Homens (CS_SEXO = ‘M’) recebem:
CS_GESTANT = 6 (não se aplica)
PUERPERA = 2 (não puérpera)
Mulheres com valores ausentes nessas variáveis recebem valor 9 (ignorado).
7. Imputação de Valores Faltantes com 9
Criada uma lista de variáveis categóricas e booleanas.
Valores ausentes nestas variáveis foram imputados com 9, representando “ignorado” conforme padrão da base.
8. Conversão de Tipos e Limpeza Fina
Conversão de colunas numéricas float64 para Int64, preservando NaN.
Remoção de registros com:
Idade negativa (NU_IDADE_N < 0)
SG_UF = '9' (ignorado)
CS_GESTANT = 0 (substituído por 9)
Verificação de colunas com tipos mistos usando uma função auxiliar.
Conversão para Int64 nas colunas problemáticas (CS_ESCOL_N, RAIOX_RES, CRITERIO).
Conversão de SG_UF para string para evitar problemas futuros com merge e visualização.
Analise Exploratória
Código
# Garante melhor visualização dos gráficossns.set(style="whitegrid")# Converter datas para datetimedados_filtrados['DT_NOTIFIC'] = pd.to_datetime(dados_filtrados['DT_NOTIFIC'], errors='coerce')# Converter UF para string (se for categórica ou numérica)dados_filtrados['SG_UF'] = dados_filtrados['SG_UF'].astype(str)
Código
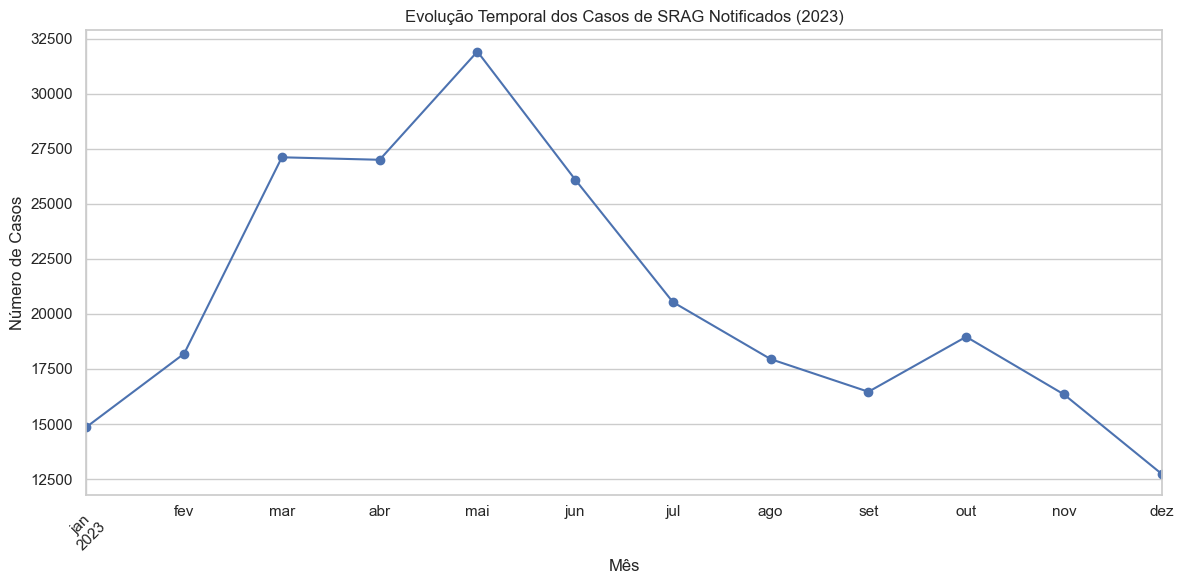
# Garantir que a coluna está em datetimedados_filtrados['DT_NOTIFIC'] = pd.to_datetime(dados_filtrados['DT_NOTIFIC'], errors='coerce')# Filtrar apenas o ano de 2023dados_2023 = dados_filtrados[dados_filtrados['DT_NOTIFIC'].dt.year ==2023]# Casos por mêscasos_por_mes = dados_2023['DT_NOTIFIC'].dt.to_period('M').value_counts().sort_index()casos_por_mes.index = casos_por_mes.index.to_timestamp()# Plotplt.figure(figsize=(12, 6))casos_por_mes.plot(marker='o')plt.title("Evolução Temporal dos Casos de SRAG Notificados (2023)")plt.xlabel("Mês")plt.ylabel("Número de Casos")plt.xticks(rotation=45)plt.tight_layout()plt.show()
Ao observar a evolução temporal dos casos de SRAG notificados ao longo do ano de 2023, é possível identificar uma clara sazonalidade. O número de notificações apresenta uma tendência de alta nos primeiros meses do ano, atingindo um pico no mês de maio. A partir desse ponto, os casos começam a diminuir progressivamente até setembro, com uma leve retomada em outubro, seguida por nova queda nos dois últimos meses do ano.
Esse padrão é compatível com o comportamento sazonal de infecções respiratórias, que tendem a se intensificar nos meses mais úmidos e frios, especialmente no outono e inverno. A elevação significativa entre março e maio reforça a importância de estratégias de prevenção nesse período, como campanhas de vacinação e reforço nos protocolos de vigilância.
A leve alta observada em outubro também merece atenção, pois pode indicar uma segunda onda menor ou variações regionais/climáticas que impactam na notificação.
Código
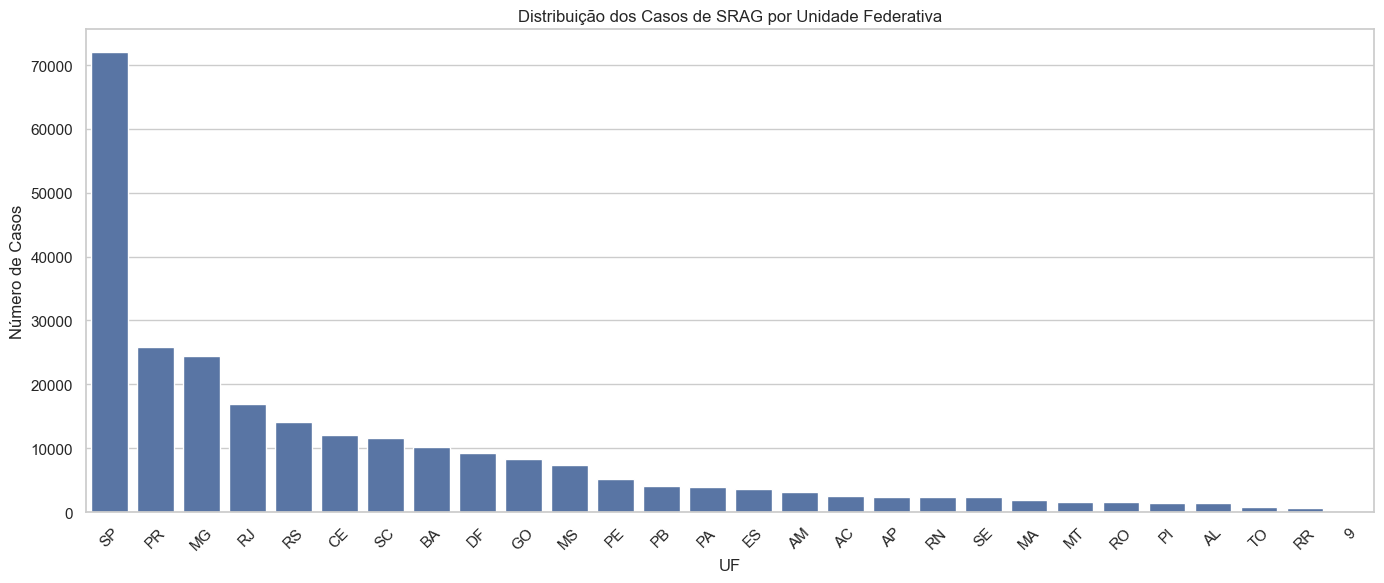
plt.figure(figsize=(14, 6))sns.countplot(data=dados_filtrados, x='SG_UF', order=dados_filtrados['SG_UF'].value_counts().index)plt.title("Distribuição dos Casos de SRAG por Unidade Federativa")plt.xlabel("UF")plt.ylabel("Número de Casos")plt.xticks(rotation=45)plt.tight_layout()plt.show()
A distribuição dos casos de SRAG por estado revela uma forte concentração em alguns centros populacionais do país. O estado de São Paulo (SP) lidera com ampla margem, representando sozinho uma fração significativa das notificações. Em seguida, aparecem Paraná (PR), Minas Gerais (MG) e Rio de Janeiro (RJ), todos com volume expressivo de registros.
Essa concentração pode ser explicada por uma combinação de fatores: maior densidade populacional, maior capacidade de testagem e vigilância, além de redes hospitalares mais estruturadas, que favorecem a notificação completa dos casos.
Estados com menor número de notificações não devem ser interpretados como menos afetados, necessariamente. É possível que haja subnotificação devido a limitações de acesso ao sistema de saúde, capacidade laboratorial ou barreiras regionais à vigilância ativa.
Essa análise geográfica reforça a importância de regionalizar estratégias de prevenção, priorizando ações mais intensivas nos estados com maior volume de casos e, ao mesmo tempo, fortalecer a vigilância em regiões historicamente menos estruturadas para que haja equidade na resposta em saúde pública.
Código
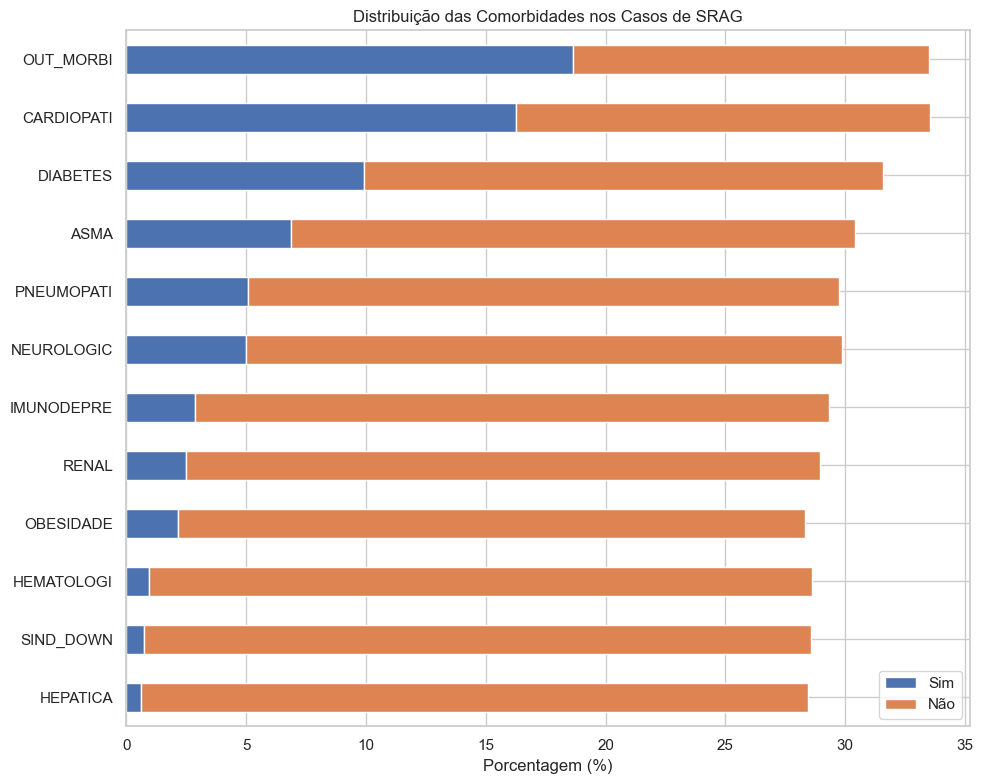
comorbidades = ['CARDIOPATI', 'HEMATOLOGI', 'SIND_DOWN', 'HEPATICA', 'ASMA','DIABETES', 'NEUROLOGIC', 'PNEUMOPATI', 'IMUNODEPRE','RENAL', 'OBESIDADE', 'OUT_MORBI']dados_filtrados_analise = dados_filtrados.copy()# Converter para object antes de substituirdados_filtrados_analise[comorbidades] = dados_filtrados_analise[comorbidades].astype("object")# Agora pode fazer o replace sem errodados_filtrados_analise[comorbidades] = dados_filtrados_analise[comorbidades].replace({1: 'Sim',2: 'Não',9: 'Ignorado'})comorb_count = {}for col in comorbidades: comorb_count[col] = dados_filtrados_analise[col].value_counts(normalize=True) *100# Exibir como gráficocomorb_df = pd.DataFrame(comorb_count).T[['Sim', 'Não']].fillna(0)comorb_df.sort_values("Sim", ascending=True).plot(kind="barh", figsize=(10, 8), stacked=True)plt.title("Distribuição das Comorbidades nos Casos de SRAG")plt.xlabel("Porcentagem (%)")plt.tight_layout()plt.show()
A análise das comorbidades entre os casos de SRAG revela que a presença de condições pré-existentes é bastante comum, embora varie bastante entre os tipos de comorbidade. As categorias com maior prevalência entre os casos são “Outras Morbidades”, “Cardiopatia” e “Diabetes”. Essas três condições representam as comorbidades mais frequentemente relatadas, e refletem o perfil típico de vulnerabilidade frente a doenças respiratórias graves.
Outras comorbidades como asma, pneumopatias crônicas e distúrbios neurológicos também aparecem em proporções relevantes, reforçando a necessidade de atenção especial a esses grupos.
Já condições como hepatopatias, síndrome de Down e doenças hematológicas aparecem com menor frequência, o que pode indicar uma menor incidência ou uma subnotificação desses fatores nos sistemas de informação.
É importante ressaltar que a presença de múltiplas comorbidades em um mesmo paciente não está capturada nesse gráfico, mas representa um fator de risco ainda maior para agravamento e óbito. Essa análise serve como base para identificar grupos de maior risco, que devem ser priorizados em estratégias de prevenção, atendimento precoce e vacinação.
Código
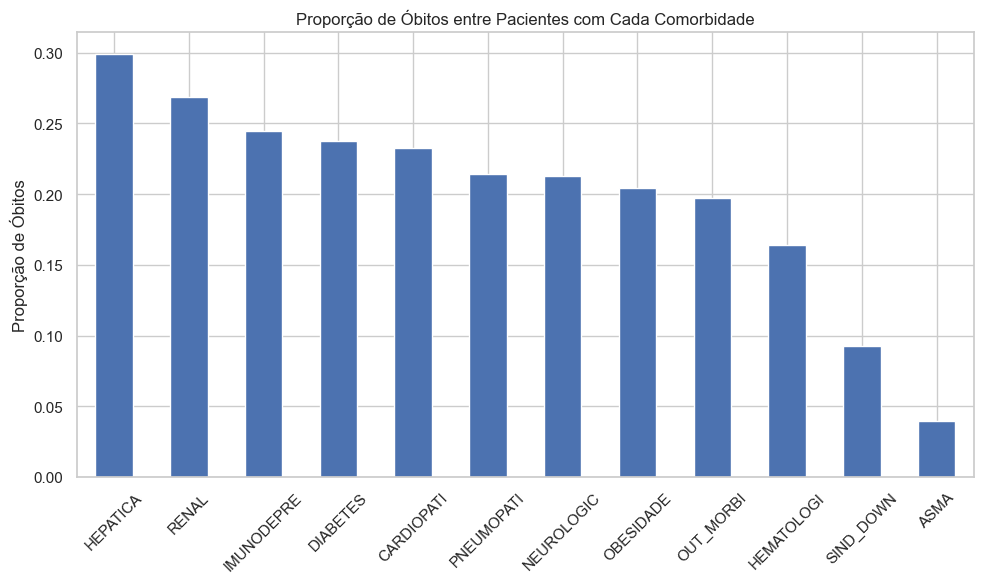
dados_filtrados_analise["EVOLUCAO_BIN"] = dados_filtrados_analise["EVOLUCAO"].map({1: 0, 2: 1})# Proporção de óbitos por comorbidadecomorb_mortalidade = {}for col in comorbidades: subset = dados_filtrados_analise[dados_filtrados_analise[col] =='Sim'] taxa_obito = subset['EVOLUCAO_BIN'].mean() # média = proporção de óbitos comorb_mortalidade[col] = taxa_obitocomorb_mortalidade = pd.Series(comorb_mortalidade).sort_values(ascending=False)plt.figure(figsize=(10, 6))comorb_mortalidade.plot(kind='bar')plt.title("Proporção de Óbitos entre Pacientes com Cada Comorbidade")plt.ylabel("Proporção de Óbitos")plt.xticks(rotation=45)plt.tight_layout()plt.show()
Este gráfico traz uma perspectiva mais crítica ao mostrar a letalidade associada a cada comorbidade nos casos de SRAG. Ao contrário do gráfico anterior, que mostra apenas a presença das condições, aqui observamos quais comorbidades estão mais associadas ao desfecho de óbito.
Hepatopatias lideram com a maior proporção de óbitos entre os pacientes que as apresentam, seguidas de perto por doenças renais e imunodeficiências. Isso sugere que, embora essas condições sejam menos prevalentes na amostra geral, elas representam um risco significativamente maior de mortalidade quando presentes.
Comorbidades mais comuns como diabetes, cardiopatia e pneumopatias também aparecem com alta taxa de letalidade, reforçando seu papel como fatores de risco críticos para desfechos graves.
Por outro lado, condições como asma, síndrome de Down e doenças hematológicas, apesar de estarem presentes em alguns casos, estão associadas a taxas de óbito relativamente mais baixas, o que pode indicar menor risco ou melhor manejo clínico desses pacientes em contextos de SRAG.
Essas informações são essenciais para priorização clínica: pacientes com hepatopatias, doença renal crônica, imunossupressão e doenças metabólicas devem ser monitorados com maior rigor desde os primeiros sintomas. Além disso, esses achados podem orientar campanhas específicas de vacinação, ações preventivas e protocolos hospitalares diferenciados para grupos de maior risco.
Código
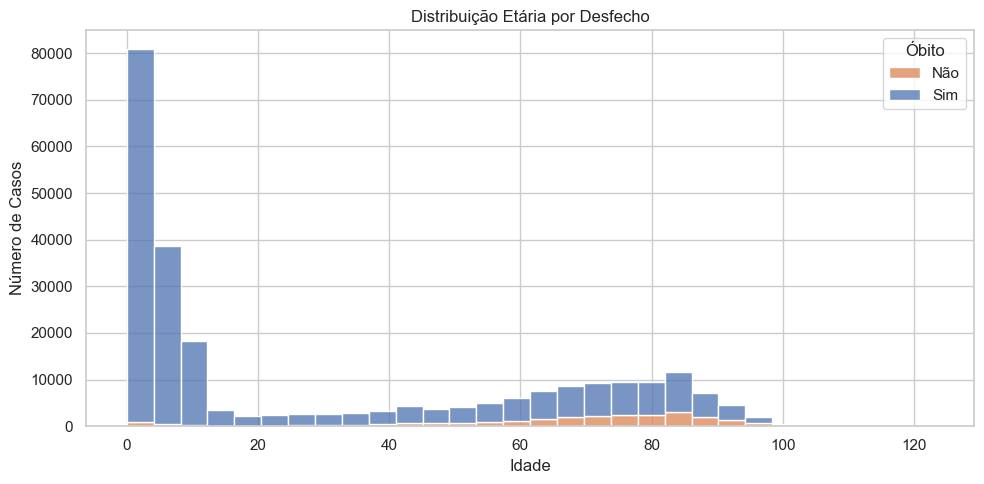
# Comparação entre óbitos e não óbitosplt.figure(figsize=(10, 5))sns.histplot(data=dados_filtrados_analise, x='NU_IDADE_N', hue='EVOLUCAO_BIN', bins=30, kde=False, multiple="stack")plt.title('Distribuição Etária por Desfecho')plt.xlabel('Idade')plt.ylabel('Número de Casos')plt.legend(title='Óbito', labels=['Não', 'Sim'])plt.tight_layout()plt.show()
A análise da distribuição etária por desfecho mostra um padrão claro e esperado: os óbitos por SRAG estão fortemente concentrados nas faixas etárias mais elevadas. O volume de casos em geral é muito alto em crianças de 0 a 5 anos, mas com predomínio de evolução não fatal. Já entre adultos e idosos, especialmente a partir dos 60 anos, observa-se uma inversão: a quantidade de óbitos passa a superar a de sobreviventes.
Essa diferença de perfil etário é fundamental para políticas de prevenção. Enquanto crianças são frequentemente internadas por SRAG, os idosos são os que mais evoluem para óbito, mesmo com menor número absoluto de internações.
Isso reforça a importância de estratégias específicas por faixa etária: vigilância ativa e ampliação de testagem em crianças; priorização de vacinação, atendimento precoce e protocolos intensivos para idosos e portadores de comorbidades.
Código
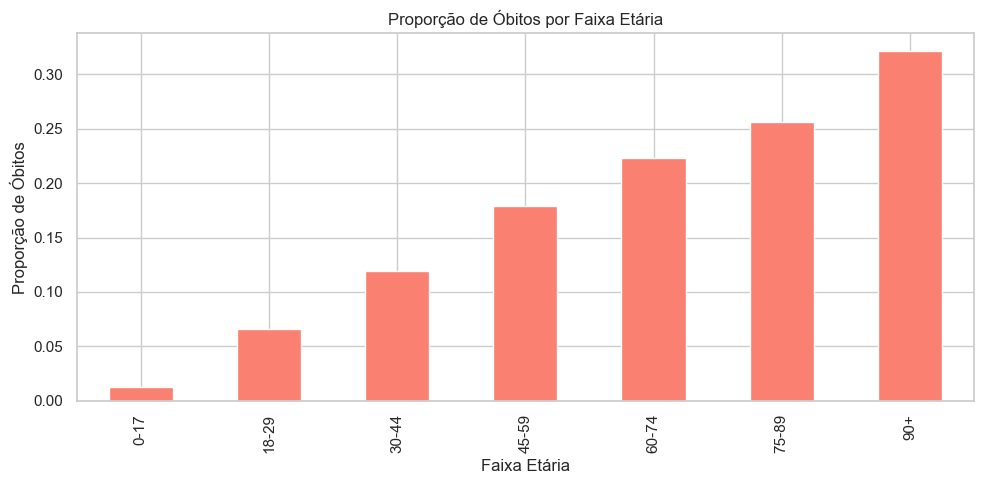
# Criar faixas etáriasbins = [0, 18, 30, 45, 60, 75, 90, 150]labels = ['0-17', '18-29', '30-44', '45-59', '60-74', '75-89', '90+']dados_filtrados_analise['faixa_etaria'] = pd.cut(dados_filtrados_analise['NU_IDADE_N'], bins=bins, labels=labels, right=False)# Proporção de óbitos por faixaproporcao_obitos = dados_filtrados_analise.groupby('faixa_etaria')['EVOLUCAO_BIN'].mean()# Plotplt.figure(figsize=(10, 5))proporcao_obitos.plot(kind='bar', color='salmon')plt.title('Proporção de Óbitos por Faixa Etária')plt.ylabel('Proporção de Óbitos')plt.xlabel('Faixa Etária')plt.tight_layout()plt.show()
C:\Users\luisf\AppData\Local\Temp\ipykernel_9672\4223826105.py:7: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
proporcao_obitos = dados_filtrados_analise.groupby('faixa_etaria')['EVOLUCAO_BIN'].mean()
A curva de letalidade por faixa etária revela uma relação clara e crescente entre idade e risco de morte por SRAG. A taxa de óbito é muito baixa em indivíduos com até 17 anos, mas aumenta de forma progressiva a partir dos 30 anos, atingindo valores críticos a partir dos 60.
O grupo com maior vulnerabilidade é o de 90 anos ou mais, com uma taxa de óbito superior a 30% dos casos registrados. Essa escalada de risco reforça a idade como um dos fatores preditores mais relevantes para a evolução desfavorável em casos de SRAG.
Essas evidências corroboram a necessidade de priorização dos idosos em políticas de prevenção, vigilância e tratamento precoce. O gráfico também reforça que, embora comorbidades sejam relevantes, a idade por si só já representa um risco elevado que precisa ser monitorado de forma ativa.
Código
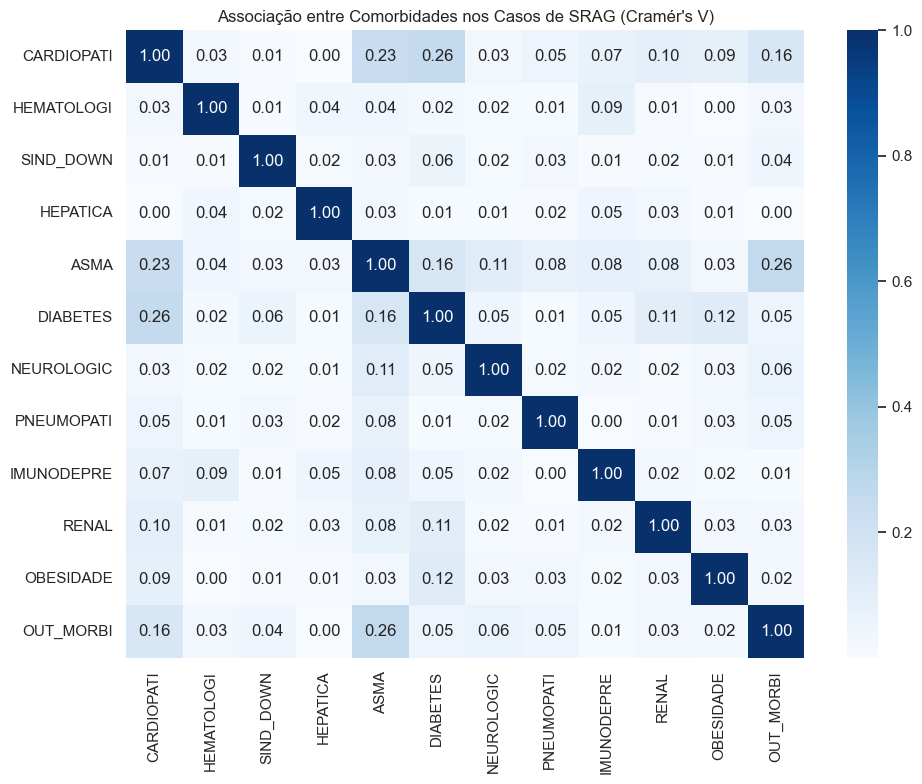
# Lista de comorbidadescomorbidades = ['CARDIOPATI', 'HEMATOLOGI', 'SIND_DOWN', 'HEPATICA', 'ASMA','DIABETES', 'NEUROLOGIC', 'PNEUMOPATI', 'IMUNODEPRE','RENAL', 'OBESIDADE', 'OUT_MORBI']# Substituir 'Sim', 'Não', 'Ignorado' por 1, 0, NaNcomorb_bin = dados_filtrados_analise[comorbidades].replace({'Sim': 1,'Não': 0,'Ignorado': np.nan})# Remover linhas com valores ausentescomorb_bin = comorb_bin.dropna()# Função de Cramér’s Vdef cramers_v(x, y): tabela = pd.crosstab(x, y) chi2 = chi2_contingency(tabela, correction=False)[0] n = tabela.sum().sum() phi2 = chi2 / n r, k = tabela.shapereturn np.sqrt(phi2 /min(k -1, r -1))# Criar matrizcramers_matrix = pd.DataFrame(np.zeros((len(comorb_bin.columns), len(comorb_bin.columns))), columns=comorb_bin.columns, index=comorb_bin.columns)for col1 in comorb_bin.columns:for col2 in comorb_bin.columns: cramers_matrix.loc[col1, col2] = cramers_v(comorb_bin[col1], comorb_bin[col2])# Plot do heatmapplt.figure(figsize=(10, 8))sns.heatmap(cramers_matrix, annot=True, cmap='Blues', fmt=".2f")plt.title("Associação entre Comorbidades nos Casos de SRAG (Cramér's V)")plt.tight_layout()plt.show()
C:\Users\luisf\AppData\Local\Temp\ipykernel_9672\4165944106.py:9: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
comorb_bin = dados_filtrados_analise[comorbidades].replace({
Associação entre Comorbidades nos Casos de SRAG (Cramér’s V) Utilizando o coeficiente de Cramér’s V, mais apropriado para variáveis binárias, foi possível avaliar a associação entre comorbidades de forma mais robusta. Ainda que a maioria das correlações se mantenha fraca, alguns padrões relevantes se destacam.
As associações mais fortes observadas foram entre:
Diabetes e Cardiopatia (V = 0.26)
Asma e Outras Morbidades (V = 0.26)
Cardiopatia e Asma (V = 0.23)
Essas combinações refletem agrupamentos clínicos plausíveis, especialmente entre condições metabólicas (diabetes e cardiopatias) e perfis respiratórios. Ainda que os coeficientes estejam abaixo de 0.3 — o que indica associação moderada — eles apontam para a presença de subgrupos de pacientes com perfis mais complexos, o que pode ser relevante para protocolos de triagem e manejo hospitalar.
Por outro lado, diversas comorbidades seguem apresentando baixa associação entre si, sugerindo que elas ocorrem de forma relativamente independente na base, ou que há possível subnotificação ou ausência de vínculos diretos entre essas condições no contexto da SRAG.
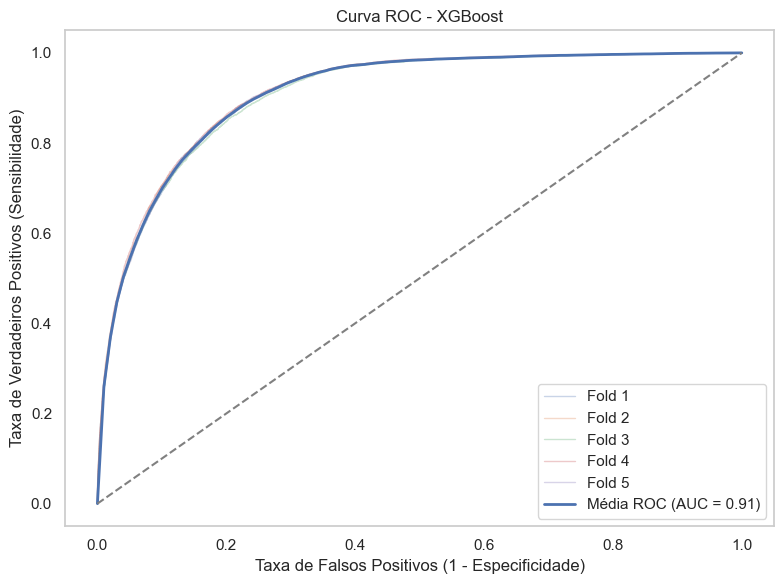
=== Métricas Médias da Validação Cruzada (5-Fold) ===
Acurácia: 0.919
Precisão: 0.647
Recall (Sensibilidade): 0.411
F1-score: 0.502
AUC: 0.910
Exemplo de matriz de confusão no último fold:
[[44038 1202]
[ 2889 2031]]
Sensibilidade (Recall): 0.413
Especificidade: 0.973
Análise Comparativa: Regressão Logística vs. XGBoost
Desempenho Geral dos Modelos
Os dois modelos testados — Regressão Logística e XGBoost — apresentaram bons desempenhos, mas com focos distintos. O XGBoost teve melhor desempenho geral nas métricas de acurácia, precisão, F1-score e AUC, o que indica que ele conseguiu um melhor equilíbrio entre classes e acertos totais. No entanto, a Regressão Logística se destacou fortemente na sensibilidade (recall), identificando uma proporção muito maior dos casos positivos (óbitos).
Isso sugere que, enquanto o XGBoost teve um desempenho mais robusto e conservador, a Regressão Logística foi mais agressiva na detecção de óbitos, mesmo ao custo de maior número de falsos positivos.
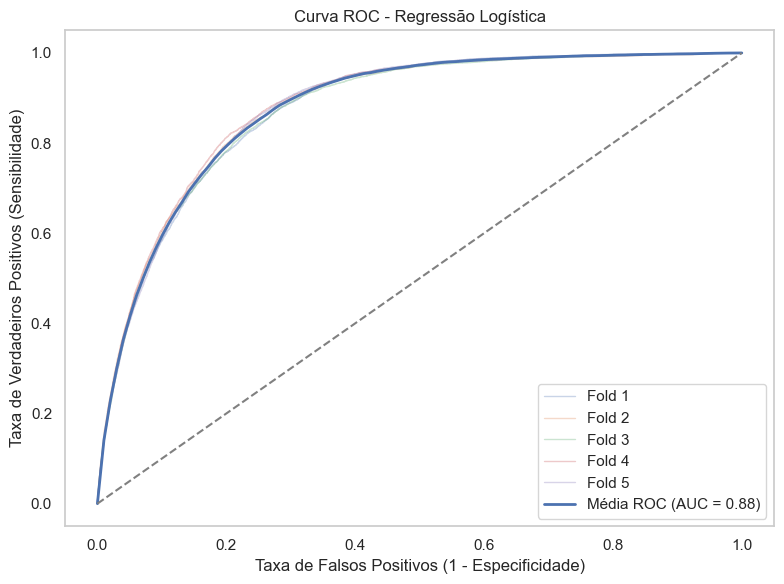
Interpretação das Métricas
A Regressão Logística apresentou uma acurácia média de 0.779 e um AUC de 0.878, com sensibilidade de 0.826 e especificidade de 0.774. Já o XGBoost apresentou acurácia média de 0.919 e AUC de 0.910, mas com recall consideravelmente menor (0.411), embora com alta especificidade (0.973).
Esses resultados evidenciam que o XGBoost tem um viés maior para reduzir falsos positivos (alto controle sobre o erro tipo I), enquanto a Regressão Logística tende a reduzir falsos negativos (erro tipo II), o que pode ser crucial em contextos sensíveis como o de prever óbitos.
Considerações sobre o Pré-processamento
No caso da Regressão Logística, foi necessário realizar pré-processamento mais elaborado, incluindo transformação de variáveis categóricas via OneHotEncoder e padronização de variáveis numéricas. Já o XGBoost foi aplicado sobre dados numéricos padronizados, mas sem a necessidade de encoding de variáveis categóricas, pois apenas variáveis numéricas foram utilizadas.
Esse ponto destaca uma vantagem prática do XGBoost em fluxos com menos tratamento categórico, embora isso também tenha limitado o volume de informação processada quando comparado à abordagem da Regressão Logística.
Papel do SMOTE
O uso do SMOTE em ambos os modelos foi fundamental para balancear as classes antes do treinamento. Como a base original era desbalanceada (com muito mais casos de não-óbito), o SMOTE ajudou os modelos a aprenderem representações mais equilibradas.
Contudo, é importante ressaltar que o SMOTE foi aplicado somente nos dados de treino dentro de cada fold da validação cruzada, evitando vazamento de informação e garantindo uma avaliação honesta. Mesmo assim, o uso do SMOTE pode gerar exemplos sintéticos que aumentam o risco de overfitting, principalmente em modelos mais complexos como o XGBoost.
Transparência e Interpretabilidade
A Regressão Logística tem vantagem clara em interpretabilidade. Cada coeficiente do modelo pode ser diretamente interpretado como a influência (positiva ou negativa) de uma variável na chance de óbito. Isso é especialmente importante em áreas como saúde pública, onde a explicabilidade do modelo pode ter tanto peso quanto sua acurácia.
O XGBoost, por outro lado, é mais opaco. Embora existam ferramentas como SHAP para análise de importância de features, o modelo em si não oferece uma explicação direta de suas decisões. Por isso, em contextos em que a transparência é essencial, a Regressão Logística pode ser preferida, mesmo com desempenho ligeiramente inferior.
Portanto, ambos os modelos são válidos e apresentam pontos fortes distintos. O XGBoost tem desempenho global superior e é indicado quando o objetivo é maximizar acerto geral com baixo erro tipo I. A Regressão Logística é mais transparente e sensível, sendo mais adequada quando o foco está em capturar todos os possíveis casos positivos, mesmo ao custo de mais falsos positivos.
A escolha entre os dois modelos depende, portanto, dos objetivos específicos da aplicação: controle rigoroso de erros ou sensibilidade e interpretabilidade.
Conclusão e Recomendações
Conclusão
A análise da base de dados de SRAG 2023 permitiu identificar padrões relevantes associados à evolução dos casos hospitalizados. O processo de limpeza e tratamento da base foi essencial para garantir a qualidade dos dados, removendo colunas com alta taxa de nulos e mantendo apenas registros com desfecho claramente definido (óbito ou não óbito).
A aplicação de modelos de machine learning mostrou que tanto a Regressão Logística quanto o XGBoost foram eficazes em identificar os casos positivos (óbitos), com o XGBoost apresentando desempenho geral superior em métricas como acurácia, precisão, F1-score e AUC. Contudo, a Regressão Logística demonstrou maior sensibilidade, sendo mais eficaz na identificação de óbitos, embora com menor precisão.
O uso do SMOTE foi essencial para equilibrar as classes, considerando a proporção inicial desbalanceada entre óbitos e não óbitos. Ao ser aplicado apenas sobre os dados de treino em cada fold da validação cruzada, foi possível evitar vazamento de informação e garantir uma avaliação mais fiel do desempenho dos modelos.
Recomendações
Monitoramento de Grupos de Risco: Com base nas variáveis mais influentes nos modelos (como idade, comorbidades e uso de suporte ventilatório), recomenda-se um acompanhamento mais próximo dos pacientes que apresentam essas características no momento da notificação.
Capacitação para Profissionais de Saúde: A interpretação dos modelos pode ser utilizada para treinar equipes médicas e de vigilância sobre os principais fatores de risco associados a desfechos graves, contribuindo para decisões mais rápidas e eficazes.
Investimentos em Dados e Sistemas: A qualidade do dado inicial impacta diretamente os modelos preditivos. Melhorar os sistemas de notificação e preenchimento de campos importantes pode aumentar ainda mais o poder preditivo de modelos futuros.
Uso Integrado de Modelos: Em ambientes críticos como saúde pública, a combinação entre modelos mais sensíveis (como Regressão Logística) e mais específicos (como o XGBoost) pode ser útil para estratégias distintas, como triagem inicial e confirmação de risco.
Atualização Contínua do Modelo: Dado o caráter sazonal e mutável das síndromes respiratórias, é recomendável que os modelos sejam recalibrados periodicamente com dados mais recentes, incorporando possíveis mudanças no perfil clínico e nos desfechos dos pacientes.
Essas recomendações podem servir de base para políticas públicas mais direcionadas à prevenção e à mitigação de óbitos por SRAG, utilizando a ciência de dados como apoio estratégico na tomada de decisão.